FastSeries ブログ
2025/10/21
音声認識とは?AIを導入した仕組みやメリットを徹底解説
- AI
- 業務効率化
- 音声認識






音声認識技術は、スマートスピーカーや翻訳アプリ、議事録作成、コンタクトセンター支援など、様々な場面で活用されていて、私たちの生活やビジネスに欠かせない存在となりつつあります。しかし、音声認識とはそもそもどのような仕組みなのか、AIはどのように活用されているのか、具体的に理解している方はまだそれほど多くないのではないでしょうか。
本記事では、音声認識の基礎から仕組み、AIとの関係、メリット、活用事例まで徹底的に解説します。
- AI
- 業務効率化
- 音声認識
音声認識技術は、スマートスピーカーや翻訳アプリ、議事録作成、コンタクトセンター支援など、様々な場面で活用されていて、私たちの生活やビジネスに欠かせない存在となりつつあります。しかし、音声認識とはそもそもどのような仕組みなのか、AIはどのように活用されているのか、具体的に理解している方はまだそれほど多くないのではないでしょうか。
本記事では、音声認識の基礎から仕組み、AIとの関係、メリット、活用事例まで徹底的に解説します。
音声認識の基本とAIとの関係
音声認識とは?
音声認識とは、人間が発する声を解析し、デジタルデータ(テキスト)に変換して出力する技術です。
例えば、SiriやGoogleアシスタントのように、スマートフォンの音声入力機能やスマートスピーカーへの話しかけで音楽を再生する操作などは、アプリケーションの技術の一部に音声認識技術が組み込まれています。
音声認識とAIの関係性
音声認識技術はAI(人工知能)と密接に関連しており、特にディープラーニング(深層学習)と呼ばれるAI技術が重要な役割を担っています。
従来の音声認識技術は、特定のフレーズや音声パターンに基づいて動作していましたが、ディープラーニングの導入により、精度や処理能力が大幅に向上しました。
ディープラーニングは、人間の脳の神経回路(ニューラルネットワーク)の仕組みを模倣した多層構造のコンピューターシステムで、大量のデータを自動解析し、そのデータの特徴を抽出する技術です。
画像認識、音声認識、自動運転、NLP(自然言語処理)など、分野によってはまだ課題もありますが、従来は困難だった高度なタスクもディープラーニングを含む機械学習技術によって精度が向上しています。
音声認識では、音声をテキストやデジタル命令に変換する際にディープラーニングが活用されることが多いです。その後、NLPによる文脈解析を行い、さらなる処理を実行することで、より高度な応用が可能になります。
AIを活用した音声認識の変遷と仕組み
AI技術を活用した近年の音声認識では、モデルの構造として「DNN-HMM型」と「End-to-End型」に大きく分類されます。
■音声認識とAI技術の変遷
| 年代 | 技術の変遷 |
| 1990年代まで | 個々の音声データの時系列を解析し蓄積した音響モデルから、どのような時系列データを生成されやすいのか確率を推定する「GMM-HMM」が主流 |
| 2010年代 | AI技術の発展によるアルゴリズム改善やGPUなどのハードウェアの発展を受け、従来のGMM(ガウス混合モデル)より、高精度に処理するDNN(ディープニューラルネットワーク)を採用し音声認識の精度を高めた「DNN-HMM型」が主流に |
| 2016年以降 | AIを用いた音声認識技術が発展し、新たに「End-to-End型」が誕生。研究分野では「End-to-End型」が主流になりつつあるが、製品として実用される場面においては「DNN-HMM型」が多く用いられる |
音声認識は主に音響分析、変換、出力という流れで進み、仕組みを紐解くとDNN-HMM型の場合は以下のプロセスで構成されています。
音響分析
音声信号はアナログ波形として記録されるため、発話された音声のままではコンピューターで処理できません。そのため、まずは入力された音声をデジタルデータに変換します。
そして、音声の特徴量(データの中から本質的な情報やパターンを数値的に表現したもの)を抽出し、周囲のノイズ除去や音量正規化などの前処理を行います。
音響モデルの処理
音響モデルでは、音声データから抽出された特徴量を基に、どの音素(言語の最小単位)に対応するかを確率的に推定します。例えば、「おんせい」という発話では音素でいうと「o-N-s-e-i」で、「o」から「N」への移動や、最後の「i」までの推測により、「おんせい」「おんせん」など複数の確率を考慮しつつも「おんせい」の確率が高い、といったスコアを算出するということです。
このプロセスでは、音声の特徴量を正確に捉えることが重要で、DNNを使うことで高い精度で推定できます。
発音辞書の参照
音響モデルによって得られた音素に対応する確率情報を基に、発音辞書を参照します。
発音辞書は、単語とその音素列の対応を示すもので、例えば「音声」「温製」「温泉」のような単語と読み、「o-N-s-e-i」「o-N-s-e-N」といった音素の表記を紐づけています。この情報を用いて音素の候補を具体的な単語候補に変換します。
言語モデルの適用
発音辞書によって生成された単語候補をさらに絞り込むために、言語モデルを適用します。
言語モデルは、文法や単語の出現確率に基づいて、最も自然な単語列や文章を選択します。例えば、音声認識中に「おんせい」と聞き取られた場合、文脈に応じて「音声」や「温製」のような適切な単語を選択します。
出力
最終的に、音声認識システムは自然な日本語の文章や、システムが理解できるコマンドを生成します。例えば、「温製料理を何か考えて」という音声入力に対して、「おすすめの温製料理は~」といったテキストを出力したり、スマートデバイスの操作指示を実行したりします。
■音声認識AIのプロセス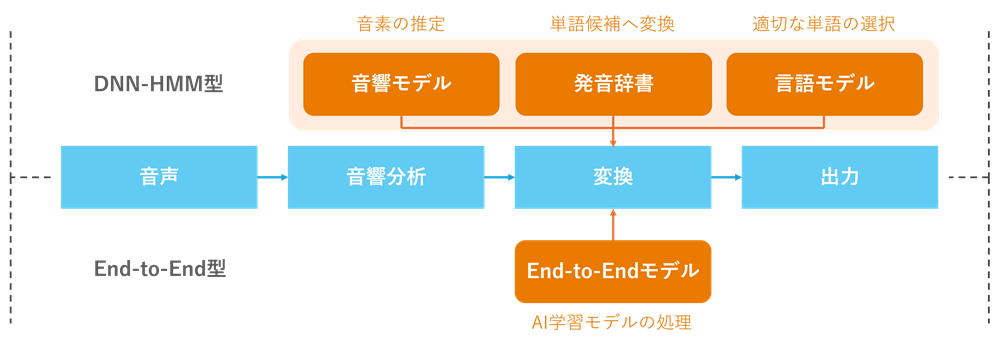
ちなみに、End-to-End型は音響モデル、発音辞書、言語モデルの部分が単一のニューラルネットワークになっているためそれぞれを用意しなくてもよいものの、専門用語などの単語追加や大量の学習データの必要性などカスタマイズにコストが多くかかるデメリットもあります。
AIを活用した音声認識のメリット
これまで挙げてきた認識精度の向上のほか、業務効率化やアクセシビリティの向上、データ活用など、音声認識にAIを活用することで得られるメリットは多岐にわたります。
業務効率化
AIの活用でリアルタイム処理能力が向上したことにより、会議やインタビュー、講演などの音声を瞬時にテキスト化することが可能です。従来は手動やタイピングでメモに膨大な労力と時間がかかっていましたが、手間が省けるだけでなく情報の正確性を保ちながら記録を残すことができます。
さらに、音声入力でハンズフリー操作が可能なため、現場作業や運転中といった手が離せない状況でも安全性を保ちつつ便利に利用できます。
情報伝達の円滑化
音声認識AIによりリアルタイムで字幕を自動生成することができ、耳が聞こえにくい方など、より多くの人に情報を届けられるようになっています。
また、多言語の音声をリアルタイムで翻訳し、異なる言語を話す人とのコミュニケーションを円滑にしています。
データ分析基盤の構築
音声認識AIを用いて、音声データをテキスト化して蓄積することで、NLPを活用したデータ分析の基盤を構築します。
コンタクトセンター(コールセンター)ではVOCとして、顧客の声や感情の傾向をより正確に把握できるため、マーケティングやサービス改善、CX(顧客体験)の向上に役立ちます。
コールセンターでの音声認識サービスについては、以下記事でも解説しています。
コールセンター向けAI音声認識サービスとは?導入メリットや注意点を解説
AIを活用した音声認識の課題
方言やアクセントへの対応不足
現状、多くの音声認識システムは標準語や主要なアクセントに基づいてトレーニングされています。そのため、特定の地域や国のアクセント、方言に対応するにはさらなるデータ学習が必要です。
また、言語には文化的背景や表現の多様性が含まれていることもあり、一概に正確に捉えることは容易ではありません。
プライバシーとセキュリティの懸念
音声認識技術が普及するにつれ、音声データの取り扱いに関するプライバシーやセキュリティの問題が注目されています。音声データには個人の特徴、場合によっては機密情報や個人情報の保護に関する懸念があるため、音声データの収集や保存に関しては注意が必要です。
顧客の同意を得る明確なガイドラインを設けたり、データの匿名化や暗号化技術を活用したりすることで、安心して技術を利用できる環境を整備しましょう。
ノイズの影響
音声認識技術は、ノイズの影響を受けやすいという課題を抱えています。風切り音やオフィスでの電話呼出音といった環境ノイズ、咳や息継ぎのような音声ノイズまで、様々な音を拾ってしまうことで認識精度が低下することがあります。
また、話者のマイクデバイスの品質や位置に依存する部分も大きいです。
そのため、マイクに口を近く寄せて話す、発声のボリュームを上げる、騒音が少ない環境に移動するといった物理的な対策から、フィルタリング技術など雑音を排除する機能を利用する、特定の音声パターンを学習させるといった技術的な対策まで広く検討することも重要です。
音声認識AIの活用例
文字起こし
会議の音声をリアルタイムで文字化し、共有や編集を効率化します。会議そのものに集中できる環境が整うとともに、後から情報検索や共有が容易になり、企業内の知見共有の円滑化にもつながっています。
また、医療現場では診療記録の自動作成、教育現場では講義内容の文字起こしなどにも活用されています。
コンタクトセンターにおいては、通話内容を自動的に記録し、要約を生成する機能を備えた音声認識AIもあります。応対履歴を記録するためのACW(後処理時間)を削減し、オペレーターがより多くの顧客へ対応することを実現します。
■FastGenieによる対話内容要約、自動分類転記、VOC蓄積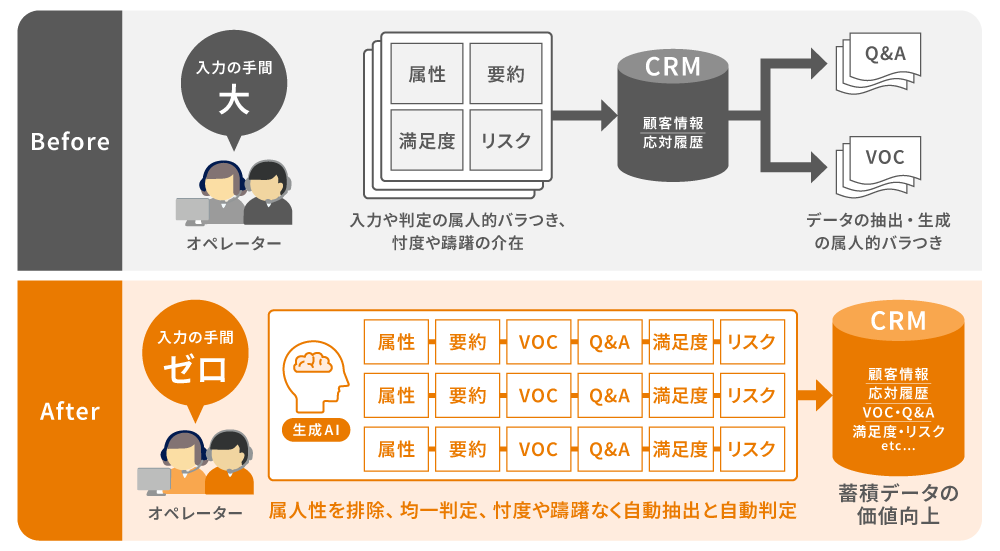
テクマトリックスが提供する生成AI機能群「FastGenie」は、顧客との対話内容をリアルタイムに要約・カテゴリ毎に自動分類・CRMへ転記します。効率化と属人性軽減を叶えたVOCの蓄積に活用することが可能です。
翻訳・通訳
異なる言語間の会話を即座に翻訳し、多言語コミュニケーションを支援します。国際的なビジネスや教育、観光業などさまざまな分野で活用されています。
リスク検出
コンプライアンス面でも音声認識AIは有効です。通話記録などを証跡として保存し、禁止ワードやNG対応を検出、品質管理を強化することで、法的リスクの軽減が期待できます。
また、コンタクトセンターにおいては、音声認識AIが顧客の声のトーンや単語の選び方を解析することで感情の変化を読み取り、怒りや不満といったクレームの兆候を早期に察知します。SVにもアラートが通知されることで、迅速なフォロー対応を可能します。結果として、トラブルの未然防止や顧客満足度の低下予防につなげられます。
ボイスボット
ボイスボットは、人間のオペレーターの代わりに顧客からの音声による問合わせに対応し、回答や指示で自動応答するシステムです。
例えば、FAQ応答を行ったり、顧客が電話でボイスボットに対して予約の変更やサービスの申込みを音声で指示することで、自動的に処理を進めたりすることができます。
NLPを活用して顧客とのやりとりの中で文脈を理解し、柔軟な対応が可能なシステムもあります。
テクマトリックスが提供するボイスボット「FastVoice」は、顧客へのヒアリングや資料請求受付対応などの一次問合わせを効率的に処理し、必要に応じて人間のオペレーターに引き継ぎます。
まとめ
- 音声認識は、音声をテキストやデジタル指示に変換する技術で、AIやディープラーニングを活用して認識精度を上げ、「業務効率化」「情報伝達の円滑化」「データ分析基盤の構築」にも貢献しています。
- 音声認識AI技術のモデルとしては、「DNN-HMM型」と「End-to-End型」に大きく分類され、主に音響分析、変換、出力というプロセスを行っています。
- 音声認識AIの活用例として、「文字起こし」「翻訳・通訳」「リスク検出」「ボイスボット」が挙げられます。
音声認識技術は、私たちの生活やビジネスを支える重要な技術として進化を続けています。課題はあるものの、技術の進化により、方言やノイズへの対応、プライバシー保護などの問題は徐々に解決されつつあります。
音声認識AIの導入を検討している方は、この記事で紹介した仕組みや活用事例を参考にしてみてください。







