Speech Recognition คืออะไร?เจาะลึกการทำงานร่วมกับ AI และประโยชน์ต่อธุรกิจ
แชร์บทความนี้

ในปัจจุบัน เทคโนโลยีการจดจำเสียง (Speech Recognition) ได้เข้ามามีบทบาทและถูกนำไปใช้งานอย่างแพร่หลายในหลากหลายภาคส่วน ไม่ว่าจะเป็นลำโพงอัจฉริยะ (Smart Speakers), แอปพลิเคชันแปลภาษา, การจัดทำรายงานการประชุม ตลอดจนการสนับสนุนงานในศูนย์บริการลูกค้า (Contact Center) จนปฏิเสธไม่ได้ว่าเทคโนโลยีนี้ได้กลายเป็นส่วนสำคัญที่ขาดไม่ได้ทั้งในชีวิตประจำวันและการดำเนินธุรกิจ
อย่างไรก็ตาม อาจยังมีผู้คนจำนวนไม่น้อยที่ยังไม่เข้าใจอย่างชัดเจนว่า แท้จริงแล้วระบบจดจำเสียงมีกระบวนการทำงานอย่างไร และเทคโนโลยี AI เข้ามามีส่วนช่วยขับเคลื่อนระบบนี้ในรูปแบบใดบ้าง
บทความชิ้นนี้จะพาคุณไปทำความเข้าใจ ตั้งแต่พื้นฐานของระบบจดจำเสียง กลไกการทำงานเชิงลึก ความสัมพันธ์ระหว่างระบบนี้กับ AI ตลอดจนประโยชน์และกรณีศึกษาการใช้งานจริง (Use Cases) อย่างครบถ้วน
ผสานพลัง Generative AI, CRM, FAQ, แชท, Voice และ IVR ได้อย่างยืดหยุ่นในระบบเดียว
ทีมงานดูแลและติดต่อกลับคุณหลังส่งคำขอ
เริ่มต้นปรึกษาได้ทันที แม้อยู่ในช่วงศึกษาและเปรียบเทียบข้อมูล
พื้นฐานของระบบจดจำเสียงและความสัมพันธ์กับ AI
ระบบจดจำเสียง (Speech Recognition) คืออะไร?
ระบบจดจำเสียง คือ เทคโนโลยีที่ทำหน้าที่วิเคราะห์เสียงพูดของมนุษย์ และแปลงผลลัพธ์ให้ออกมาเป็นข้อมูลดิจิทัลในรูปแบบของข้อความ (Text)
ตัวอย่างที่เห็นได้ชัดคือ การนำเทคโนโลยีนี้ไปผสานรวมกับแอปพลิเคชันต่าง ๆ ในชีวิตประจำวัน เช่น ฟังก์ชันการพิมพ์ด้วยเสียงบนสมาร์ตโฟน หรือการสั่งเปิดเพลงด้วยเสียงผ่านลำโพงอัจฉริยะอย่าง Siri และ Google Assistant เป็นต้น
ความสัมพันธ์ระหว่างระบบจดจำเสียงกับ AI
เทคโนโลยีการจดจำเสียงมีความเกี่ยวพันอย่างลึกซึ้งกับ AI (ปัญญาประดิษฐ์) โดยเฉพาะอย่างยิ่ง เทคโนโลยี AI ที่เรียกว่า Deep Learning (การเรียนรู้เชิงลึก) ซึ่งเข้ามามีบทบาทสำคัญเป็นอย่างมาก
ในอดีต เทคโนโลยีการจดจำเสียงจะทำงานโดยอิงจากวลีหรือแพตเทิร์นเสียงที่ถูกกำหนดไว้ล่วงหน้าเท่านั้น แต่การเข้ามาของ Deep Learning ได้ช่วยยกระดับทั้งความแม่นยำและขีดความสามารถในการประมวลผลให้สูงขึ้นกว่าเดิมอย่างมหาศาล
Deep Learning คืออะไร? ระบบคอมพิวเตอร์ที่มีโครงสร้างซับซ้อนหลายชั้น ซึ่งจำลองรูปแบบการทำงานมาจากเครือข่ายประสาทในสมาร์ทของมนุษย์ (Neural Networks) มีความสามารถในการวิเคราะห์ข้อมูลจำนวนมหาศาลและดึงคุณลักษณะเด่น (Features) ของข้อมูลนั้นออกมาได้โดยอัตโนมัติ
แม้ว่าในบางสาขา เช่น ระบบจดจำภาพ (Image Recognition), ระบบขับเคลื่อนอัตโนมัติ (Autonomous Driving) และการประมวลผลภาษาธรรมชาติ หรือ NLP (Natural Language Processing) จะยังคงมีข้อจำกัดและสิ่งท้าทายที่ต้องแก้ไขอยู่บ้าง แต่ปฏิเสธไม่ได้ว่า เทคโนโลยีการเรียนรู้ของเครื่อง (Machine Learning) รวมถึง Deep Learning ได้เข้ามาช่วยเพิ่มความแม่นยำในการทำงานที่ซับซ้อน ซึ่งในอดีตเคยเป็นเรื่องยากให้ประสบความสำเร็จได้ดีขึ้นอย่างมาก
สำหรับในระบบจดจำเสียงนั้น Deep Learning มักถูกนำมาใช้ในขั้นตอนการแปลงเสียงพูดให้กลายเป็นข้อความหรือคำสั่งดิจิทัล จากนั้นระบบจะนำคำศัพท์เหล่านั้นไปวิเคราะห์บริบทเชิงลึกต่อด้วยเทคโนโลยี NLP เพื่อให้สามารถตอบสนองและประมวลผลในระดับที่ขั้นสูงขึ้นต่อไปได้
วิวัฒนาการและกลไกการทำงานของระบบจดจำเสียงที่ขับเคลื่อนด้วย AI
ในปัจจุบัน ระบบจดจำเสียงที่ใช้เทคโนโลยี AI จะถูกแบ่งโครงสร้างโมเดลออกเป็น 2 ประเภทหลัก ๆ ได้แก่ “รูปแบบ DNN-HMM” และ “รูปแบบ End-to-End”
■ วิวัฒนาการของระบบจดจำเสียงและเทคโนโลยี AI
| ยุค | วิวัฒนาการทางเทคโนโลยี |
| ก่อนปี 1990 | โมเดลกระแสหลักคือ “GMM-HMM” ซึ่งทำงานโดยการประมาณค่าความน่าจะเป็นในการสร้างข้อมูลอนุกรมเวลา (Time-series data) จากโมเดลเสียง (Acoustic Models) ที่ทำหน้าที่วิเคราะห์และสะสมข้อมูลอนุกรมเวลาของสัญญาณเสียงแต่ละตัว |
| ทศวรรษ 2010 | ด้วยการพัฒนาอัลกอริทึมของ AI และความก้าวหน้าของฮาร์ดแวร์อย่าง GPU ส่งผลให้โมเดลแบบ “DNN-HMM” กลายมาเป็นกระแสหลักแทน โดยโมเดลนี้ใช้โครงข่ายประสาทเทียมเชิงลึก (DNN) เพื่อการประมวลผลที่แม่นยำสูงและช่วยเพิ่มความถูกต้องในการจดจำเสียงให้เหนือกว่าโมเดล GMM แบบดั้งเดิม |
| ตั้งแต่ปี 2016 เป็นต้นมา | เทคโนโลยีการจดจำเสียงที่ใช้ AI ได้ก้าวหน้าขึ้นจนนำไปสู่การเกิดโมเดลใหม่ที่เรียกว่า “End-to-End” แม้ว่าในแวดวงการวิจัย โมเดลแบบ End-to-End จะกำลังเป็นที่นิยมอย่างมาก แต่ในแง่ของการนำไปใช้งานจริงกับผลิตภัณฑ์เชิงพาณิชย์ โมเดลแบบ “DNN-HMM” ยังคงเป็นที่นิยมและใช้งานแพร่หลายมากกว่า |
โดยทั่วไป ระบบจดจำเสียงจะมีกระบวนการหลัก ๆ คือ การวิเคราะห์คลื่นเสียง, การแปลงข้อมูล และการแสดงผลลัพธ์ หากเราเจาะลึกกลไกการทำงานของโมเดลรูปแบบ DNN-HMM จะสามารถแบ่งออกเป็นขั้นตอนได้ดังนี้
การวิเคราะห์สัญญาณเสียง (Acoustic Analysis)
เนื่องจากสัญญาณเสียงที่ถูกบันทึกมาจะอยู่ในรูปแบบของคลื่นอะนาล็อก (Analog Waveform) คอมพิวเตอร์จึงยังไม่สามารถประมวลผลเสียงพูดนั้นได้ทันที ดังนั้น เสียงที่รับเข้ามาจึงต้องถูกแปลงให้เป็นข้อมูลดิจิทัลก่อน จากนั้นระบบจะดึงคุณลักษณะเด่นของเสียง (Voice Features – ค่าตัวเลขที่แสดงถึงข้อมูลสำคัญหรือแพตเทิร์นของเสียง) พร้อมทั้งทำความสะอาดข้อมูล เช่น การตัดเสียงรบกวนรอบข้าง (Noise Cancellation) และการปรับระดับความดังของเสียงให้เท่ากัน (Volume Normalization)
การประมวลผลด้วยโมเดลเสียง (Processing of Acoustic Models)
โมเดลเสียงจะนำคุณลักษณะเด่นที่ดึงออกมาจากข้อมูลเสียง มาคำนวณตามหลักความน่าจะเป็นว่าเสียงนั้นตรงกับ “หน่วยเสียง” (Phoneme) ใด (หน่วยเสียงคือหน่วยที่เล็กที่สุดของภาษา) ยกตัวอย่างเช่น ในคำว่า “onsei” (แปลว่า เสียง) จะประกอบด้วยหน่วยเสียง “o-N-s-e-i” ระบบจะไล่พิจารณาตั้งแต่เสียง “o” ไป “N” จนถึง “i” ตัวสุดท้าย เพื่อคำนวณคะแนนความน่าจะเป็นเทียบกับคำที่ใกล้เคียงกัน เช่น “onsei” กับ “onsen” (แปลว่า น้ำพุร้อน) และเลือกคำว่า “onsei” ที่ได้คะแนนความน่าจะเป็นสูงกว่า ซึ่งการใช้ DNN จะช่วยให้ระบบจับคุณลักษณะเด่นของเสียงและประมวลผลขั้นตอนนี้ได้อย่างแม่นยำสูงมาก
การอ้างอิงพจนานุกรมคำอ่าน (Pronunciation Dictionary Reference)
เมื่อได้ข้อมูลความน่าจะเป็นของหน่วยเสียงจากโมเดลเสียงแล้ว ระบบจะนำไปเทียบกับพจนานุกรมคำอ่าน เพื่อดูความสอดคล้องกันระหว่างคำศัพท์กับลำดับของหน่วยเสียง เช่น การจับคู่คำว่า “on-gin”, “onsei”, “onsen” เข้ากับรหัสหน่วยเสียง เช่น o-N-s-e-i หรือ o-N-s-e-N เพื่อแปลงจากกลุ่มหน่วยเสียงที่มีโอกาสเป็นไปได้ ให้กลายมาเป็นตัวเลือกคำศัพท์ที่เป็นรูปธรรม
การประยุกต์ใช้โมเดลภาษา (Application of Language Models)
เพื่อคัดเลือกคำศัพท์ที่ระบบเจนออกมาให้แคบลงและตรงกับความจริงที่สุด ระบบจะนำ โมเดลภาษา (Language Models) มาปรับใช้ โมเดลนี้จะเลือกกลุ่มคำหรือประโยคที่เรียงต่อกันแล้วดูเป็นธรรมชาติที่สุดตามหลักไวยากรณ์และความน่าจะเป็นในการเกิดคำนั้น ๆ เช่น หากระบบจดจำเสียงได้คำว่า “onsei” โมเดลภาษาจะวิเคราะห์บริบทโดยรอบเพื่อเลือกคำแปลหรือตัวอักษรคันจิที่ถูกต้อง (เช่น เลือกคำว่า “เสียง” ไม่ใช่ “น้ำพุร้อน”) ให้สอดคล้องกับเนื้อหาที่กำลังพูดอยู่
การประมวลผลลัพธ์และสั่งการ (Output Generation)
ในท้ายที่สุด ระบบจดจำเสียงจะแปลงผลลัพธ์ออกมาเป็นข้อความภาษาที่สละสลวยเป็นธรรมชาติ หรือแปลงเป็นชุดคำสั่งที่ระบบคอมพิวเตอร์เข้าใจ ตัวอย่างเช่น เมื่อเราพูดว่า “ช่วยคิดเมนูอาหารนึ่งให้หน่อย” ระบบก็จะแสดงผลลัพธ์ออกมาเป็นข้อความว่า “เมนูอาหารนึ่งที่แนะนำคือ…” หรือแปลงเป็นคำสั่งสั่งการให้เครื่องใช้ไฟฟ้าอัจฉริยะทำงานตามที่บอกได้ทันที
■ กระบวนการทำงานของ AI ในระบบจดจำเสียง
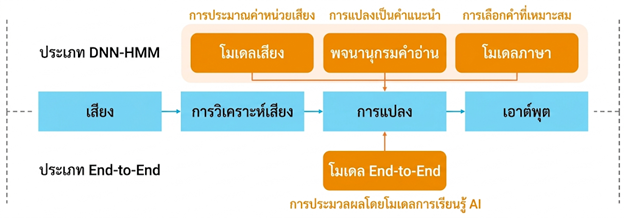
ในทางกลับกัน โมเดลแบบ End-to-End มีจุดเด่นตรงที่ไม่จำเป็นต้องแยกโครงข่ายประสาทเทียมออกเป็นโมเดลเสียง พจนานุกรมคำอ่าน และโมเดลภาษาหลาย ๆ ส่วนแบบ DNN-HMM (แต่จะรวมทุกอย่างไว้ในโครงข่ายเดียว) อย่างไรก็ตาม โมเดลนี้ก็มีข้อเสียตรงที่ปรับแต่งระบบได้ยากและมีค่าใช้จ่ายสูง เช่น การเพิ่มคำศัพท์เฉพาะทางหรือคำศัพท์ทางเทคนิคใหม่ ๆ รวมถึงจำเป็นต้องใช้ข้อมูลจำนวนมหาศาลในการฝึกฝนระบบ (Training Data)
ประโยชน์ของระบบจดจำเสียงที่ขับเคลื่อนด้วย AI
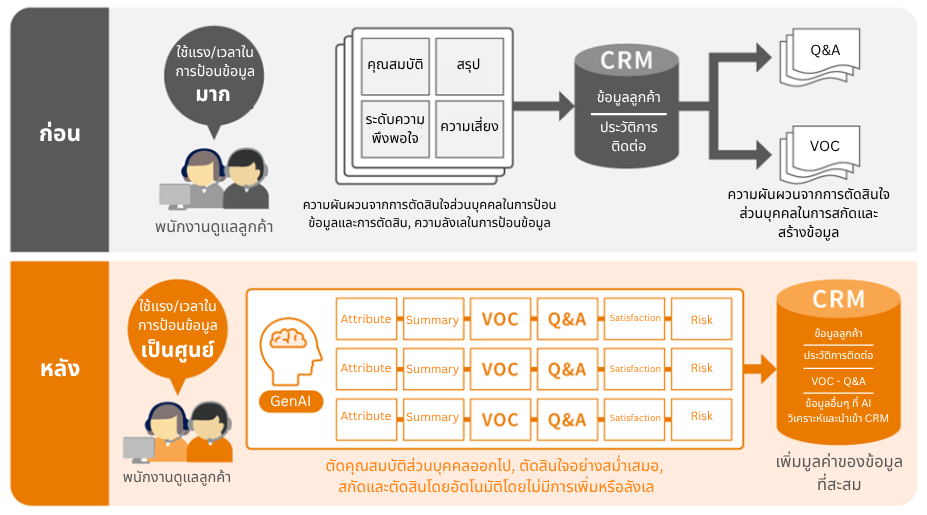
นอกจากความแม่นยำในการจดจำเสียงที่พัฒนาขึ้นอย่างก้าวกระโดดตามที่ได้กล่าวไปแล้ว การนำ AI มาประยุกต์ใช้กับระบบจดจำเสียงยังมีประโยชน์ที่หลากหลายในเชิงธุรกิจ ไม่ว่าจะเป็นการเพิ่มประสิทธิภาพการทำงาน การเปิดกว้างในการเข้าถึงข้อมูล และการนำข้อมูลไปต่อยอดให้เกิดประโยชน์สูงสุด
การเพิ่มประสิทธิภาพในการดำเนินงาน (Operational Efficiency)
ด้วยความสามารถในการประมวลผลแบบเรียลไทม์ (Real-time) ของ AI ทำให้ในปัจจุบันเราสามารถแปลงเสียงพูดจากการประชุม การสัมภาษณ์ หรือการบรรยายให้กลายเป็นข้อความได้ในทันที
จากเดิมที่ต้องใช้เวลาและแรงกายอย่างมหาศาลในการจดบันทึกหรือพิมพ์ด้วยมือ เทคโนโลยีนี้ไม่เพียงแต่จะช่วยประหยัดเวลาและทรัพยากรบุคคลเท่านั้น แต่ยังช่วยบันทึกข้อมูลได้อย่างครบถ้วนและรักษาความถูกต้องของข้อมูลไว้ได้อย่างดีเยี่ยม
นอกจากนี้ ระบบยังรองรับการสั่งการแบบแฮนด์ฟรี (Hands-free) ผ่านการป้อนข้อมูลด้วยเสียง ทำให้สามารถใช้งานได้อย่างสะดวกและปลอดภัย แม้ในสถานการณ์ที่ไม่สามารถละมือได้ เช่น ระหว่างการปฏิบัติงานหน้างาน (On-site) หรือในขณะขับรถ
การเพิ่มความคล่องตัวในการสื่อสารข้อมูล (Streamlining Communication)
AI สำหรับจดจำเสียงสามารถสร้างคำบรรยาย (Subtitles) ได้โดยอัตโนมัติแบบเรียลไทม์ ซึ่งช่วยทลายกำแพงและส่งต่อข้อมูลไปถึงผู้คนได้มากขึ้น โดยเฉพาะผู้ที่มีความบกพร่องทางการเรียนรู้หรือทางการได้ยิน
ในขณะเดียวกัน ระบบยังสามารถแปลภาษาจากเสียงพูดได้หลากหลายภาษาแบบเรียลไทม์ ช่วยให้การสื่อสารระหว่างผู้ที่ใช้ภาษาที่แตกต่างกันเป็นไปได้อย่างราบรื่นและไร้รอยต่อ
การสร้างแพลตฟอร์มเพื่อวิเคราะห์ข้อมูล (Building a Data Analysis Platform)
การใช้ AI จดจำเสียงเพื่อแปลงและจัดเก็บข้อมูลเสียงให้อยู่ในรูปแบบข้อความ ถือเป็นการวางรากฐานสำคัญสำหรับการนำข้อมูลไปวิเคราะห์ต่อยอดด้วยเทคโนโลยี NLP (การประมวลผลภาษาธรรมชาติ)
ตัวอย่างเช่น ในศูนย์บริการลูกค้า (Contact Center หรือ Call Center) ระบบนี้จะช่วยให้องค์กรเข้าใจ เสียงของลูกค้า (VOCs – Voice of Customer) รวมถึงแนวโน้มทางอารมณ์ได้อย่างแม่นยำยิ่งขึ้น ซึ่งข้อมูลเหล่านี้เป็นประโยชน์อย่างมหาศาลในการนำไปปรับปรุงกลยุทธ์การตลาด การยกระดับงานบริการ และการสร้างประสบการณ์ที่ดีให้แก่ลูกค้า (CX – Customer Experience)
ความท้าทายของระบบจดจำเสียงที่ขับเคลื่อนด้วย AI
แม้ว่าระบบจดจำเสียงจะพัฒนาไปไกลมาก แต่ในปัจจุบันก็ยังคงมีข้อจำกัดและความท้าทายบางประการที่องค์กรควรคำนึงถึง
การตอบสนองต่อภาษาถิ่นและสำเนียงที่ยังไม่ครอบคลุมพอ
ในปัจจุบัน ระบบจดจำเสียงส่วนใหญ่จะถูกฝึกฝน (Train) โดยใช้ฐานข้อมูลจากภาษากลางและสำเนียงหลักเป็นหลัก ดังนั้น จึงยังจำเป็นต้องมีการป้อนข้อมูลและฝึกฝนระบบเพิ่มเติม เพื่อให้ AI สามารถเข้าใจและประมวลผลสำเนียงเฉพาะถิ่นหรือภาษาท้องถิ่นของแต่ละภูมิภาคและแต่ละประเทศได้อย่างแม่นยำ
นอกจากนี้ เนื่องจากภาษาเป็นสิ่งที่มีมิติทางวัฒนธรรมและมีการแสดงออกที่หลากหลาย (เช่น คำสแลง หรือคำอุปมาอุปไมย) การทำให้ AI เข้าใจบริบททั้งหมดอย่างถูกต้องร้อยเปอร์เซ็นต์ด้วยโมเดลรูปแบบเดียวนั้นจึงไม่ใช่เรื่องง่าย
ความกังวลด้านความเป็นส่วนตัวและความปลอดภัย
เมื่อเทคโนโลยีการจดจำเสียงแพร่หลายมากขึ้น ประเด็นด้านความเป็นส่วนตัวและความปลอดภัยในการจัดการกับข้อมูลเสียงก็ได้รับความสนใจมากขึ้นตามไปด้วย เนื่องจากข้อมูลเสียงสามารถระบุอัตลักษณ์เฉพาะบุคคลได้ และในบางสถานการณ์ ข้อมูลที่พูดคุยอาจมีเรื่องที่เป็นความลับทางธุรกิจหรือข้อมูลส่วนบุคคลรวมอยู่ด้วย ดังนั้น การเก็บรวบรวมและการจัดเก็บข้อมูลเสียงจึงต้องทำด้วยความระมัดระวังเป็นพิเศษ
องค์กรจึงควรมีการกำหนดแนวทางปฏิบัติ (Guidelines) ที่ชัดเจนในการขอความยินยอมจากลูกค้า รวมถึงการนำเทคโนโลยีการแปลงข้อมูลให้เป็นข้อมูลนิรนาม (Data Anonymization) และการเข้ารหัสข้อมูล (Encryption) มาใช้ เพื่อสร้างสภาพแวดล้อมที่ผู้ใช้งานสามารถมั่นใจและไว้วางใจได้
ผลกระทบจากเสียงรบกวน (Noise)
หนึ่งในความท้าทายสำคัญของเทคโนโลยีจดจำเสียงคือ “ความไวต่อเสียงรบกวนรอบข้าง” หากระบบตรวจจับเสียงอื่น ๆ แทรกเข้ามา เช่น เสียงลม, เสียงโทรศัพท์ในสำนักงาน หรือแม้แต่เสียงสำลัก เสียงไอ และเสียงลมหายใจของผู้พูด ก็อาจส่งผลให้ความแม่นยำในการแปลงเสียงลดลงได้
นอกจากนี้ คุณภาพและการจัดวางตำแหน่งของไมโครโฟนที่ผู้พูดใช้งาน ก็เป็นอีกหนึ่งปัจจัยสำคัญที่มีผลต่อความแม่นยำเช่นกัน
ดังนั้น การรับมือกับปัญหานี้จึงต้องอาศัยการผสมผสานตั้งแต่ มาตรการทางกายภาพ เช่น การพูดให้ใกล้ไมโครโฟนมากขึ้น การเพิ่มระดับเสียงพูด หรือการย้ายไปคุยในสถานที่ที่ไม่มีเสียงรบกวน ไปจนถึง มาตรการทางเทคนิค เช่น การใช้ฟังก์ชันตัดเสียงรบกวน (Filtering) และการฝึกให้ AI เรียนรู้แพตเทิร์นเสียงเฉพาะเจาะจง เป็นต้น
เนื้อหาภาพรวมใกล้ครบถ้วนแล้วครับ คาดว่าส่วนถัดไปน่าจะเป็น Use Cases หรือบทสรุป สามารถส่งส่วนที่เหลือมาได้เลยนะครับ!
ตัวอย่างการประยุกต์ใช้ AI สำหรับจดจำเสียงในภาคธุรกิจ
การแปลงเสียงเป็นข้อความ (Transcription)
ระบบจะช่วยแปลงเสียงจากการประชุมเป็นข้อความแบบเรียลไทม์ ทำให้การแชร์ข้อมูลและการแก้ไขสรุปการประชุมเป็นเรื่องที่ง่ายและรวดเร็วขึ้น ช่วยสร้างสภาพแวดล้อมที่ผู้เข้าร่วมสามารถโฟกัสกับการประชุมได้อย่างเต็มที่ โดยไม่ต้องกังวลเรื่องการจดบันทึก อีกทั้งยังช่วยให้การค้นหาและส่งต่อข้อมูลในภายหลังสะดวกขึ้น ส่งเสริมการแบ่งปันความรู้ (Knowledge Sharing) ภายในองค์กรได้อย่างมีประสิทธิภาพ
นอกจากนี้ ในวงการแพทย์ยังมีการนำเทคโนโลยีนี้ไปใช้บันทึกประวัติการรักษาของคนไข้ลงในระบบโดยอัตโนมัติ และในภาคการศึกษาก็ถูกนำไปใช้ถอดความเนื้อหาการบรรยายในห้องเรียนอีกด้วย
สำหรับในศูนย์บริการลูกค้า (Contact Center) มีการนำ AI จดจำเสียงที่มีฟังก์ชันบันทึกบทสนทนาและสรุปเนื้อหาการโทรโดยอัตโนมัติมาใช้งาน ซึ่งช่วยลดเวลาการทำงานหลังวางสาย หรือ ACW (After Call Work) ในการบันทึกประวัติการให้บริการ ส่งผลให้พนักงาน (Operators) มีเวลาไปให้บริการลูกค้าท่านอื่น ๆ ได้มากขึ้น
■ ยกระดับการสรุปบทสนทนา จัดหมวดหมู่อัตโนมัติ และสะสม VOC ด้วย FastGenie
ชุดฟีเจอร์ Generative AI ของเราอย่าง “FastGenie“ มีความสามารถในการสรุปบทสนทนาของลูกค้าแบบเรียลไทม์ พร้อมจัดหมวดหมู่ประเภทการติดต่อโดยอัตโนมัติ และบันทึกข้อความลงในระบบ CRM ทันที ซึ่งโซลูชันนี้สามารถนำไปใช้ในการเก็บรวบรวม “เสียงของลูกค้า” (VOC) เพื่อเพิ่มประสิทธิภาพในการทำงาน และลดการพึ่งพาทักษะเฉพาะบุคคลได้อย่างดีเยี่ยม
การแปลและการล่าม (Translation and Interpretation)
AI สามารถแปลบทสนทนาระหว่างภาษาที่ต่างกันได้ในทันที เพื่อรองรับการสื่อสารหลายภาษา (Multilingual) โดยถูกนำไปใช้อย่างแพร่หลายในหลากหลายภาคส่วน เช่น ธุรกิจระหว่างประเทศ, การศึกษา และอุตสาหกรรมการท่องเที่ยว
การตรวจจับความเสี่ยง (Risk Detection)
AI สำหรับจดจำเสียงมีประสิทธิภาพอย่างมากในแง่ของการกำกับดูแลการปฏิบัติงานให้เป็นไปตามกฎระเบียบ (Compliance) การจัดเก็บประวัติการโทรไว้เป็นหลักฐานหลัก (Audit Trails) รวมถึงการตรวจจับคำต้องห้าม หรือการตอบกลับที่ไม่เหมาะสม (NG Responses) จะช่วยควบคุมคุณภาพการบริการและลดความเสี่ยงทางกฎหมายขององค์กรลงได้
นอกจากนี้ ในศูนย์บริการลูกค้า AI ยังสามารถวิเคราะห์น้ำเสียงและคำศัพท์ที่ลูกค้าเลือกใช้ เพื่อตรวจจับการเปลี่ยนแปลงทางอารมณ์ และส่งสัญญาณเตือนล่วงหน้าเมื่อลูกค้าเริ่มมีอาการโกรธหรือไม่พอใจ (Complaints) พร้อมส่งการแจ้งเตือนไปยังหัวหน้างาน (Supervisors) ทันที เพื่อให้เข้าช่วยเหลือหรือแก้ไขสถานการณ์ได้อย่างทันท่วงที ส่งผลให้สามารถป้องกันปัญหาก่อนที่จะบานปลาย และป้องกันไม่ให้ความพึงพอใจของลูกค้าลดลงได้
หุ่นยนต์ตอบรับด้วยเสียง (VoiceBot)
VoiceBot หรือหุ่นยนต์ตอบรับด้วยเสียง จะทำหน้าที่ตอบกลับข้อซักถามของลูกค้าด้วยเสียงแทนพนักงาน โดยระบบจะให้คำตอบหรือทำตามคำสั่งโดยอัตโนมัติ
ตัวอย่างเช่น ระบบสามารถตอบคำถามที่พบบ่อย (FAQs) หรือรับคำสั่งเสียงเพื่อเปลี่ยนวันเวลาการจอง รวมถึงการสมัครบริการต่าง ๆ ทางโทรศัพท์ โดยระบบจะดำเนินการในขั้นตอนต่อไปให้โดยอัตโนมัติ นอกจากนี้ บางระบบยังมีการนำเทคโนโลยี NLP มาใช้เพื่อให้หุ่นยนต์เข้าใจบริบทและโต้ตอบกับลูกค้าได้อย่างยืดหยุ่นเป็นธรรมชาติอีกด้วย
“FastVoice“ ซึ่งเป็นระบบ VoiceBot ของ TechMatrix สามารถช่วยจัดการกับการติดต่อเข้ามาในขั้นต้นได้อย่างมีประสิทธิภาพ เช่น การสอบถามข้อมูลเบื้องต้นจากลูกค้า หรือการรับเรื่องเพื่อขอเอกสารต่าง ๆ และระบบสามารถโอนสายส่งต่อให้กับพนักงานที่เป็นมนุษย์ดูแลต่อได้ทันทีเมื่อมีความจำเป็น
สรุป
- ระบบจดจำเสียง (Speech Recognition) คือ เทคโนโลยีที่แปลงเสียงพูดให้เป็นข้อความหรือคำสั่งดิจิทัล โดยมีการนำ AI และ Deep Learning มาใช้เพื่อยกระดับความแม่นยำในการจดจำเสียง ซึ่งมีส่วนช่วยสำคัญในการ “เพิ่มประสิทธิภาพการดำเนินงาน”, “ช่วยให้การส่งต่อข้อมูลลื่นไหลยิ่งขึ้น” และ “สร้างแพลตฟอร์มสำหรับวิเคราะห์ข้อมูล” ขององค์กร
- โมเดลเทคโนโลยี AI ในระบบจดจำเสียง สามารถแบ่งออกเป็น 2 ประเภทหลัก ๆ ได้แก่ “รูปแบบ DNN-HMM” และ “รูปแบบ End-to-End” โดยมีกระบวนการทำงานหลักคือ การวิเคราะห์สัญญาณเสียง การแปลงข้อมูล และการประมวลผลลัพธ์
- ตัวอย่างการประยุกต์ใช้ AI สำหรับจดจำเสียงในทางปฏิบัติ ได้แก่ การแปลงเสียงเป็นข้อความ (Transcription), การแปลและการล่าม, การตรวจจับความเสี่ยง และหุ่นยนต์ตอบรับด้วยเสียง
เทคโนโลยีการจดจำเสียง (Speech Recognition) ยังคงได้รับการพัฒนาอย่างต่อเนื่องในฐานะเทคโนโลยีสำคัญที่ช่วยสนับสนุนทั้งชีวิตประจำวันและการดำเนินธุรกิจ แม้จะยังคงมีความท้าทายอยู่บ้าง แต่ความก้าวหน้าทางเทคโนโลยีก็กำลังช่วยแก้ไขปัญหาต่างๆ ได้อย่างต่อเนื่อง ไม่ว่าจะเป็นการรองรับภาษาถิ่น การจัดการกับเสียงรบกวน รวมถึงการปกป้องความเป็นส่วนของข้อมูล
หากคุณกำลังพิจารณาที่จะนำ AI ระบบจดจำเสียงมาใช้งาน สามารถศึกษาและอ้างอิงจากกลไกการทำงานรวมถึงกรณีศึกษา (Use Cases) ต่างๆ ที่เราได้นำเสนอไว้ในบทความนี้
ผสานพลัง Generative AI, CRM, FAQ, แชท, Voice และ IVR ได้อย่างยืดหยุ่นในระบบเดียว
ทีมงานดูแลและติดต่อกลับคุณหลังส่งคำขอ
เริ่มต้นปรึกษาได้ทันที แม้อยู่ในช่วงศึกษาและเปรียบเทียบข้อมูล
แชร์บทความนี้


บทความยอดนิยม
ผลิตภัณฑ์ที่เกี่ยวข้อง



ยกระดับประสิทธิภาพการทำงานและคุณภาพการบริการสู่มาตรฐานใหม่
การันตีผลลัพธ์ความสำเร็จจากลูกค้าองค์กรจำนวนมาก
เริ่มต้นปรึกษาได้ทันที แม้อยู่ในช่วงศึกษาและเปรียบเทียบข้อมูล